
About a year ago (https://lkml.org/lkml/2010/6/4/272) my first patchset that laid the ground work to enable initial domain (dom0) was accepted in the Linux kernel. It was tiny: a total of around 50 new lines of code added. Great, except that it took me seven months to actually get to this stage.
It did not help that the patchset had gone through eight revisions before the maintainer decided that it he could sign off on it. Based on those time-lines I figured the initial domain support would be ready around 2022 🙂
Fast-forward to today and we have initial domain support in Linux kernel with high-performance backends.
So what made it go so much faster (or slower if you have been waiting for this since 2004)? Foremost was the technical challenge of dealing with code that “works” but hasn’t been cleaned up. This is the same problem that OEMs have when they try to upstream their in-house drivers –
the original code “works” but is a headache to maintain and is filled with #ifdef LINUX_VERSION_2_4_3, #else..
To understand why this happens to code, put yourself in the shoes of an engineer who has to deliver a product yesterday. The first iteration is minimal – just what it takes to do the the job. The  next natural step is to improve the code, clean it up, but .. another hot bug lands on the engineer’s lap, and then there isn’t enough time to go back and improve the original code. At the end of day the code is filled with weird edge cases, code paths that seemed right but maybe aren’t anymore, etc.
The major technical challenge was picking up this code years later, figuring out its peculiarities, its intended purposes and how it diverged from its intended goal, and then rewriting it correctly without breaking anything. The fun part is that it is like giving it a new life  – not only can we do it right, but we can also fix all those hacks the original code had. In the end we  (I, Jeremy Fitzhardinge, Stefano Stabellini, and Ian Campbell) ended cleaning up generic code and then alongside providing the Xen specific code. That is pretty neat.
Less technical but also important, was the challenge of putting ourselves in the shoes of a maintainer so that we could write the code to suit the maintainer. I learned this the hard way with the first patchset where it took good seven months for to me finally figure out how the maintainer wanted the code to be written – which was “with as few changes as possible.” While I was writing abstract APIs with backend engines – complete overkill. Getting it right the first time really cut down the time for the maintainer to accept the patches.
The final thing is patience – it takes time to make sure the code is solid. More than often, the third or fourth revision of the code was pretty and right. This meant that for every revision we had to redo the code, retest it, get people to review it  – and that can take quite some time. This had the effect that per merge window (every three months) we tried to upstream only one or maybe two components as we did not have any other pieces of code ready or did not feel they were ready yet. We do reviews now on xen-devel mailing list before submitting it to the Linux Kernel Mailing list (LKML) and the maintainer.
So what changed between 2.6.36 (where the SWIOTLB changes were committed) and 3.0 to make Linux kernel capable of booting as the first guest by the Xen hypervisor?
Around 600 patches. Architecturally the first component was the Xen-SWIOTLB which allowed the DMA API (used by most device drivers) to translate between the guest virtual address and the physical address (and vice versa). Then came in the Xen PCI frontend driver and the Xen PCI library (quite important). The later provided the glue for the PCI API (which mostly deals with IRQ/MSI/MSI-X) to utilize the Xen PCI frontend. This meant that when a guest tried to interrogate the PCI bus for configuration details (which you can see yourself by doing ‘lspci -v’) all those requests would be tunneled through the Xen PCI frontend to the backend. Also requests to set up IRQs or MSIs were tunneled through the Xen PCI backend. In short, we allowed PCI devices to be passed in to the Para Virtualized (PV) guests and function.
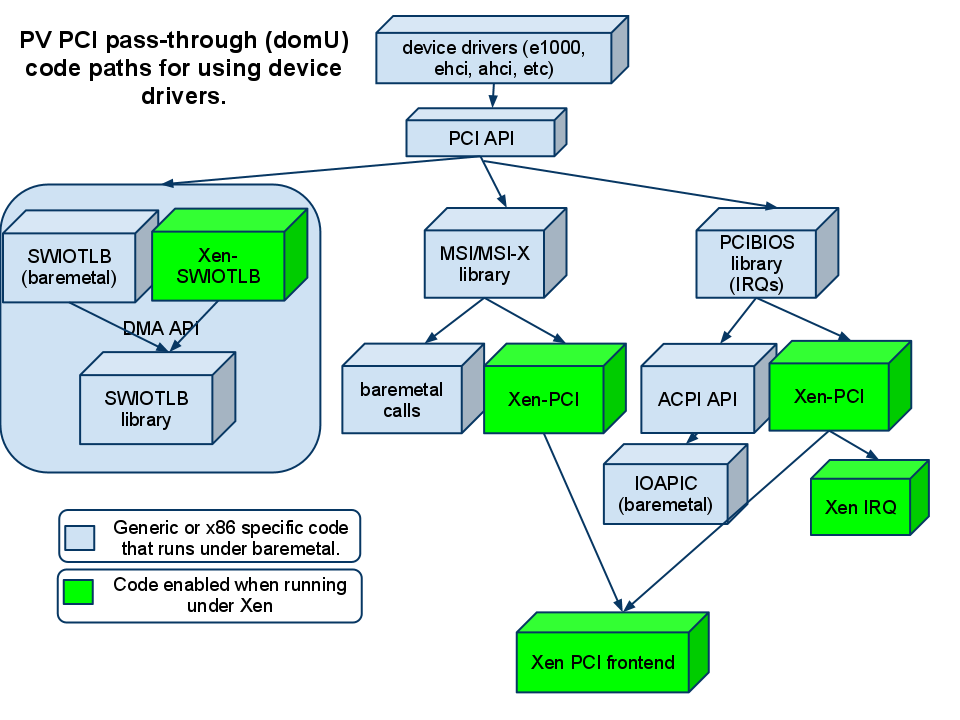
The next part was the ACPI code. The ACPI code calls the IRQ layer at bootup to tell it what device has what interrupt (ACPI _PRT tables). When the device is enabled (loaded) it calls PCI API, which in turn calls the IRQ layer, which then calls into the ACPI API. The Xen PCI (which I mentioned earlier) had provided the infrastructure to route the PCI API calls through – so we extended it and added the ACPI call-back. Which meant that it could use the ACPI API instead of the Xen PCI frontend, as appropriate – and viola, the interrupts were now enabled properly.
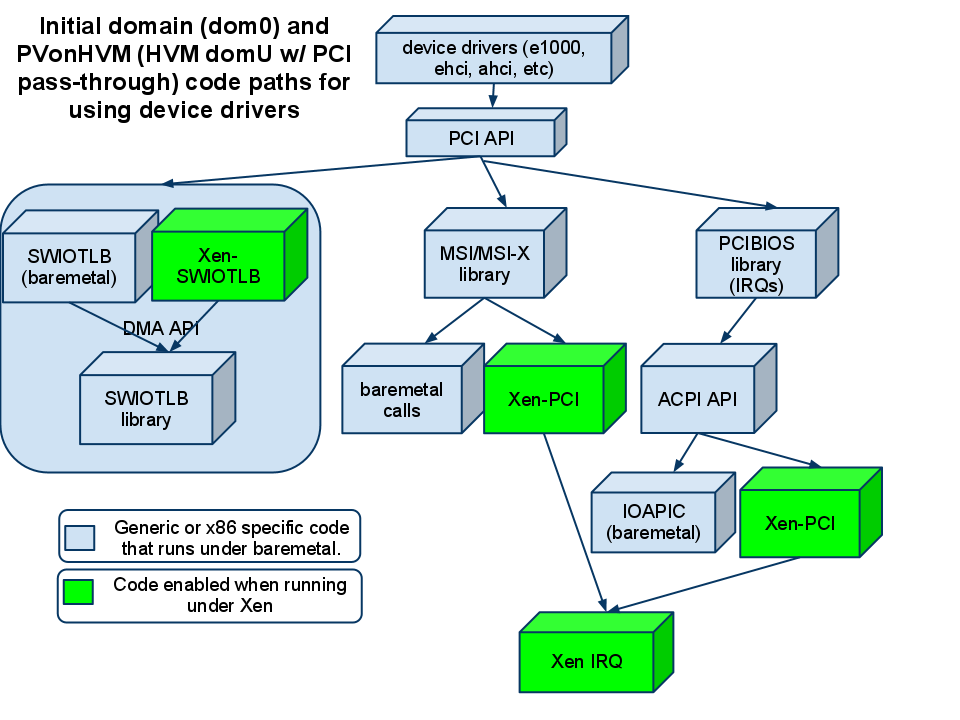
When 2.6.37 was released, the Linux kernel under the Xen hyper-visor booted! It was very limited (no backends, not all drivers worked, some IRQs never got delivered), but it kind of worked. Much rejoicing happened on Jan 4th 2011 🙂
Then we started cracking on the bugs and adding infrastructure pieces for backends. I am not going to go in details – but there were a lot of patches in many many areas. The first backend to be introduced was the xen-netback, which was accepted in 2.6.39. Â And the second one – xen-blkback – was accepted right after that in 3.0.
With Linux 3.0 we now have the major components to be classified as a working initial domain – aka – dom0.
There is still work though – we have not fully worked out the ACPI S3 and S5 support, or the 3D graphics support – but the majority of the needs will be satisfied by the 3.0 kernel.
I skimped here on the under-laying code called paravirt, which Jeremy had been working tirelessly on since 2.6.23 – and which made it all possible – but that is a topic for another article.
It did not help that the patchset had gone through eight revisions before the maintainer decided that it he could sign off on it. Based on those time-lines I figured the initial domain support would be ready around 2022 🙂
Fast-forward to today and we have initial domain support in Linux kernel with high-performance backends.
So what made it go so much faster (or slower if you have been waiting for this since 2004)? Foremost was the technical challenge of dealing with code that “works” but hasn’t been cleaned up. This is the same problem that OEMs have when they try to upstream their in-house drivers –
the original code “works” but is a headache to maintain and is filled with #ifdef LINUX_VERSION_2_4_3, #else..
To understand why this happens to code, put yourself in the shoes of an engineer who has to deliver a product yesterday. The first iteration is minimal – just what it takes to do the the job. The  next natural step is to improve the code, clean it up, but .. another hot bug lands on the engineer’s lap, and then there isn’t enough time to go back and improve the original code. At the end of day the code is filled with weird edge cases, code paths that seemed right but maybe aren’t anymore, etc.
The major technical challenge was picking up this code years later, figuring out its peculiarities, its intended purposes and how it diverged from its intended goal, and then rewriting it correctly without breaking anything. The fun part is that it is like giving it a new life  – not only can we do it right, but we can also fix all those hacks the original code had. In the end we  (I, Jeremy Fitzhardinge, Stefano Stabellini, and Ian Campbell) ended cleaning up generic code and then alongside providing the Xen specific code. That is pretty neat.
Less technical but also important, was the challenge of putting ourselves in the shoes of a maintainer so that we could write the code to suit the maintainer. I learned this the hard way with the first patchset where it took good seven months for to me finally figure out how the maintainer wanted the code to be written – which was “with as few changes as possible.” While I was writing abstract APIs with backend engines – complete overkill. Getting it right the first time really cut down the time for the maintainer to accept the patches.
The final thing is patience – it takes time to make sure the code is solid. More than often, the third or fourth revision of the code was pretty and right. This meant that for every revision we had to redo the code, retest it, get people to review it  – and that can take quite some time. This had the effect that per merge window (every three months) we tried to upstream only one or maybe two components as we did not have any other pieces of code ready or did not feel they were ready yet. We do reviews now on xen-devel mailing list before submitting it to the Linux Kernel Mailing list (LKML) and the maintainer.
So what changed between 2.6.36 (where the SWIOTLB changes were committed) and 3.0 to make Linux kernel capable of booting as the first guest by the Xen hypervisor?
Around 600 patches. Architecturally the first component was the Xen-SWIOTLB which allowed the DMA API (used by most device drivers) to translate between the guest virtual address and the physical address (and vice versa). Then came in the Xen PCI frontend driver and the Xen PCI library (quite important). The later provided the glue for the PCI API (which mostly deals with IRQ/MSI/MSI-X) to utilize the Xen PCI frontend. This meant that when a guest tried to interrogate the PCI bus for configuration details (which you can see yourself by doing ‘lspci -v’) all those requests would be tunneled through the Xen PCI frontend to the backend. Also requests to set up IRQs or MSIs were tunneled through the Xen PCI backend. In short, we allowed PCI devices to be passed in to the Para Virtualized (PV) guests and function.
The next part was the ACPI code. The ACPI code calls the IRQ layer at bootup to tell it what device has what interrupt (ACPI _PRT tables). When the device is enabled (loaded) it calls PCI API, which in turn calls the IRQ layer, which then calls into the ACPI API. The Xen PCI (which I mentioned earlier) had provided the infrastructure to route the PCI API calls through – so we extended it and added the ACPI call-back. Which meant that it could use the ACPI API instead of the Xen PCI frontend, as appropriate – and viola, the interrupts were now enabled properly.
When 2.6.37 was released, the Linux kernel under the Xen hyper-visor booted! It was very limited (no backends, not all drivers worked, some IRQs never got delivered), but it kind of worked. Much rejoicing happened on Jan 4th 2011 🙂
Then we started cracking on the bugs and adding infrastructure pieces for backends. I am not going to go in details – but there were a lot of patches in many many areas. The first backend to be introduced was the xen-netback, which was accepted in 2.6.39. Â And the second one – xen-blkback – was accepted right after that in 3.0.
With Linux 3.0 we now have the major components to be classified as a working initial domain – aka – dom0.
There is still work though – we have not fully worked out the ACPI S3 and S5 support, or the 3D graphics support – but the majority of the needs will be satisfied by the 3.0 kernel.
I skimped here on the under-laying code called paravirt, which Jeremy had been working tirelessly on since 2.6.23 – and which made it all possible – but that is a topic for another article.