
Let’s take a step back and look at the current state of virtualization in the software industry. X86 hypervisors were built to run a few different operating systems on the same machine. Nowadays they are mostly used to execute several instances of the same OS (Linux), each running a single server application in isolation. Containers are a better fit for this use case, but they expose a very large attack surface. It is possible to reduce the attack surface, however it is a very difficult task, one that requires minute knowledge of the app running inside. At any scale it becomes a formidable challenge. The 15-year-old hypervisor technologies, principally designed for RHEL 5 and Windows XP, are more a workaround than a solution for this use case. We need to bring them to the present and take them into the future by modernizing their design.
The typical workload we need to support is a Linux server application which is packaged to be self contained, complying to the OCI Image Format or Docker Image Specification. The app comes with all required userspace dependencies, including its own libc. It makes syscalls to the Linux kernel to access resources and functionalities. This is the only interface we must support.
Many of these syscalls closely correspond to function calls which are part of the POSIX family of standards. They have well known parameters and return values. POSIX stands for “Portable Operating System Interface”: it defines an API available on all major Unixes today, including Linux. POSIX is large to begin with and Linux adds its own set of non-standard calls on top of it. As a result a Linux system has a very high number of exposed calls and, inescapably, also a high number of vulnerabilities. It is wise to restrict syscalls by default. Linux containers struggle with it, but hypervisors are very accomplished in this respect. After all hypervisors don’t need to have full POSIX compatibility. By paravirtualizing hardware interfaces, Xen provides powerful functionalities with a small attack surface. But PV devices are the wrong abstraction layer for Docker apps. They cause duplication of functionalities between the guest and the host. For example, the network stack is traversed twice, first in DomU then in Dom0. This is unnecessary. It is better to raise hypervisor abstractions by paravirtualizing a small set of syscalls directly.
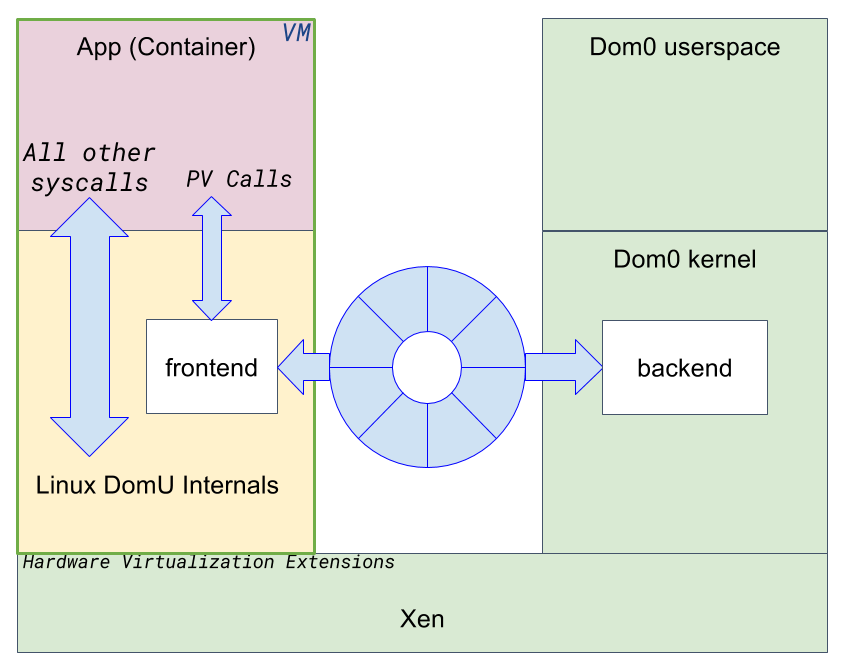
It is far easier and more efficient to write paravirtualized drivers for syscalls than to emulate hardware because syscalls are at a higher level and made for software. I wrote a protocol specification called PV Calls to forward POSIX calls from DomU to Dom0. I also wrote a couple of prototype Linux drivers for it that work at the syscall level. The initial set of calls covers socket, connect, accept, listen, recvmsg, sendmsg and poll. The frontend driver forwards syscalls requests over a ring. The backend implements the syscalls, then returns success or failure to the caller. The protocol creates a new ring for each active socket. The ring size is configurable on a per socket basis. Receiving data is copied to the ring by the backend, while sending data is copied to the ring by the frontend. An event channel per ring is used to notify the other end of any activity. This tiny set of PV Calls is enough to provide networking capabilities to guests.
We are still running virtual machines, but mainly to restrict the vast majority of applications syscalls to a safe and isolated environment. The guest operating system kernel, which is provided by the infrastructure (it doesn’t come with the app), implements syscalls for the benefit of the server application. Xen gives us the means to exploit hardware virtualization extensions to create strong security boundaries around the application. Xen PV VMs enable this approach to work even when virtualization extensions are not available, such as on top of Amazon EC2 or Google Compute Engine instances.
This solution is as secure as Xen VMs but efficiently tailored for containers workloads. Early measurements show excellent performance. It also provides a couple of less obvious advantages. In Docker’s default networking model, containers’ communications appear to be made from the host IP address and containers’ listening ports are explicitly bound to the host. PV Calls are a perfect match for it: outgoing communications are made from the host IP address directly and listening ports are automatically bound to it. No additional configurations are required.
Another benefit is ease of monitoring. One of the key aspects of hardening Linux containers is keeping applications under constant observation with logging and monitoring. We should not ignore it even though Xen provides a safer environment by default. PV Calls forward networking calls made by the application to Dom0. In Dom0 we can trivially log them and detect misbehavior. More powerful (and expensive) monitoring techniques like memory introspection offer further opportunities for malware detection.
PV Calls are unobtrusive. No changes to Xen are required as the existing interfaces are enough. Changes to Linux are very limited as the drivers are self-contained. Moreover, PV Calls perform extremely well! Let’s take a look at a couple of iperf graphs (higher is better):
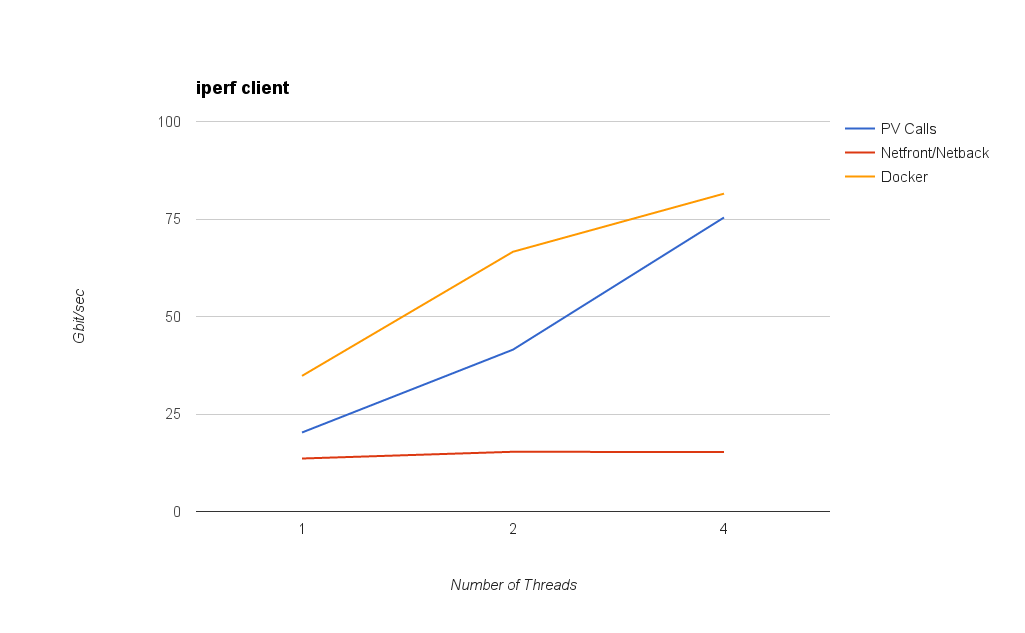
The first graph shows network bandwidth measured by running an iperf server in Dom0 and an iperf client inside the VM (or container in the case of Docker). PV Calls reach 75 gbit/sec with 4 threads, far better than netfront/netback.
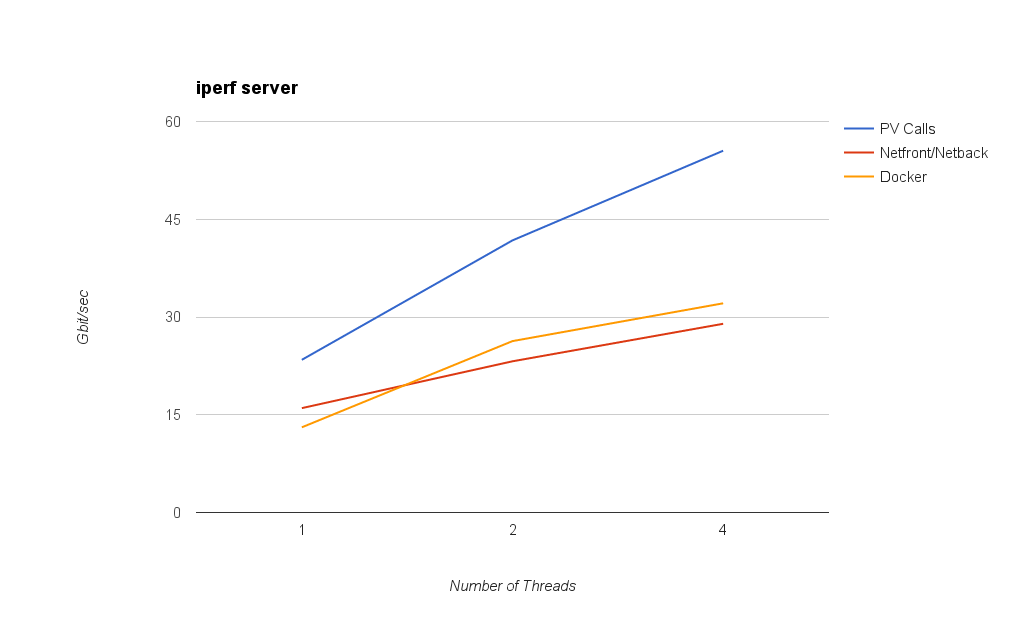
The second graph shows network bandwidth measured by running an iperf server in the guest (or container in the case of Docker) and an iperf client in Dom0. In this scenario PV Calls reach 55 gbit/sec and outperform not just netfront/netback but even Docker.
The benchmarks have been run on an Intel Xeon D-1540 machine, with 8 cores (16 threads) and 32 GB of ram. Xen is 4.7.0-rc3 and Linux is 4.6-rc2. Dom0 and DomU have 4 vcpus each, pinned. DomU has 4 GB of ram.
For more information on PV Calls, read the full protocol specification on xen-devel. You are welcome to join us and participate in the review discussions. Contributions to the project are very appreciated!